置换检验
To illustrate the basic idea of a permutation test, suppose we have two groups {A} A and {B} B whose sample means are {{A}} {x}{A} and {{B}} {x}{B}, and that we want to test, at 5% significance level, whether they come from the same distribution. Let {n_{A}} n_{A} and {n_{B}} n_{B} be the sample size corresponding to each group. The permutation test is designed to determine whether the observed difference between the sample means is large enough to reject the null hypothesis H {{0}} {0} that the two groups have identical probability distributions
The test proceeds as follows. First, the difference in means between the two samples is calculated: this is the observed value of the test statistic, T(obs). Then the observations of groups {A} A and {B} B are pooled.
Next, the difference in sample means is calculated and recorded for every possible way of dividing these pooled values into two groups of size {n_{A}} n_{A} and {n_{B}} n_{B} (i.e., for every permutation of the group labels A and B). The set of these calculated differences is the exact distribution of possible differences under the null hypothesis that group label does not matter.
The one-sided p-value of the test is calculated as the proportion of sampled permutations where the difference in means was greater than or equal to T(obs). The two-sided p-value of the test is calculated as the proportion of sampled permutations where the absolute difference was greater than or equal to ABS(T(obs)).
If the only purpose of the test is reject or not reject the null hypothesis, we can as an alternative sort the recorded differences, and then observe if T(obs) is contained within the middle 95% of them. If it is not, we reject the hypothesis of identical probability curves at the 5% significance level 显著性检验通常可以告诉我们一个观测值是否是有效的,例如检测两组样本均值差异的假设检验可以告诉我们这两组样本的均值是否相等(或者那个均值更大)。我们在实验中经常会因为各种问题(时间、经费、人力、物力)得到一些小样本结果,如果我们想知道这些小样本结果的总体是什么样子的,就需要用到置换检验
Permutation test 置换检验是Fisher于20世纪30年代提出的一种基于大量计算(computationally intensive),利用样本数据的全(或随机)排列,进行统计推断的方法,因其对总体分布自由,应用较为广泛,特别适用于总体分布未知的小样本资料,以及某些难以用常规方法分析资料的假设检验问题。在具体使用上它和Bootstrap Methods类似,通过对样本进行顺序上的置换,重新计算统计检验量,构造经验分布,然后在此基础上求出P-value进行推断
# permutation test in R
a<-c(24,43,58,67,61,44,67,49,59,52,62,50,42,43,65,26,33,41,19,54,42,20,17,60,37,42,55,28)
group<-factor(c(rep("A",12),rep("B",16)))
data<-data.frame(group,a)
find.mean<-function(x){
mean(x[group=="A",2])-mean(x[group=="B",2])
}
results<-replicate(999,find.mean(data.frame(group,sample(data[,2]))))
p.value<-length(results[results>mean(data[group=="A",2])-mean(data[group=="B",2])])/1000
hist(results,breaks=20,prob=TRUE)
lines(density(results))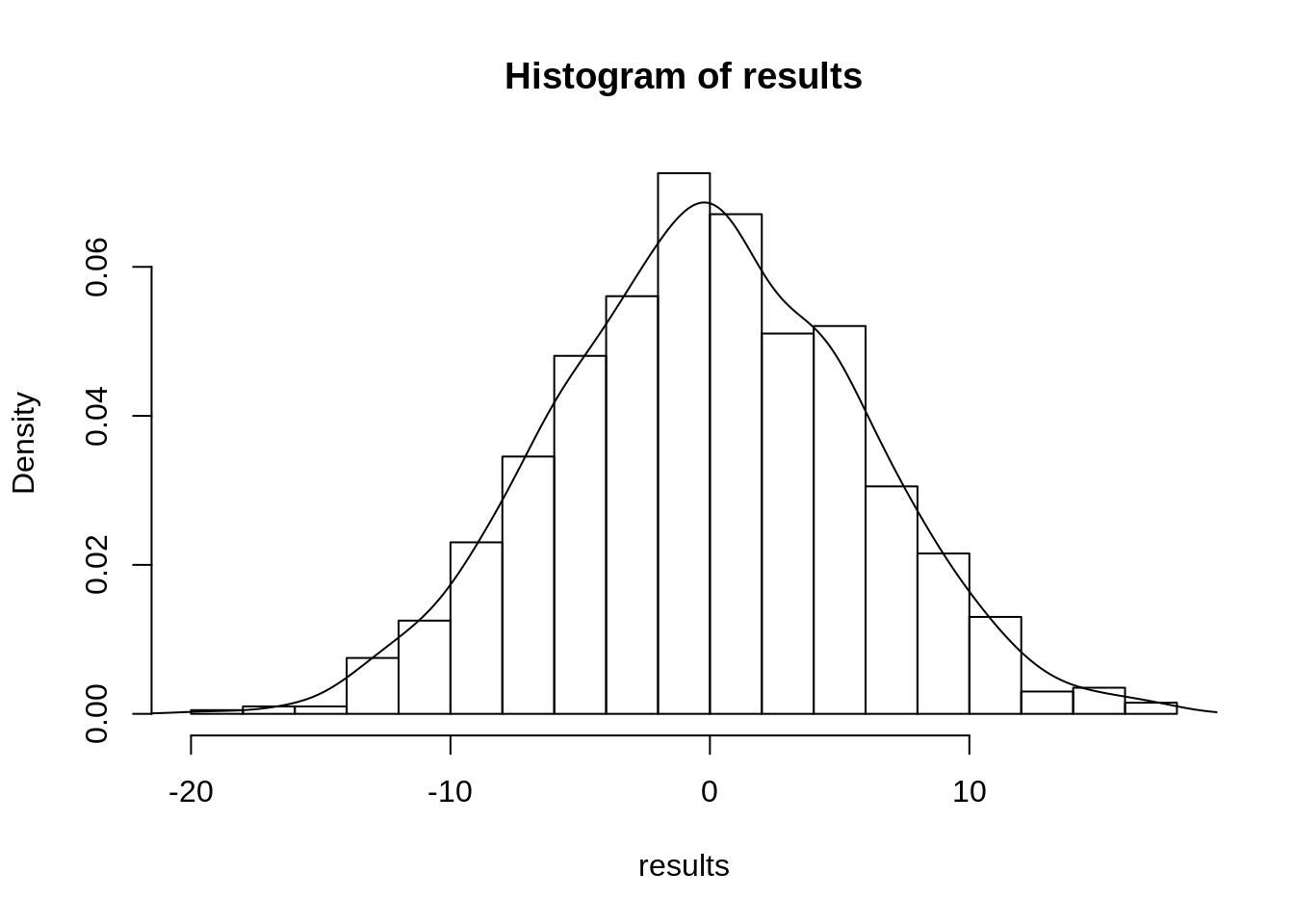 ##
##
To improve readability, only the 100 most heavily sequenced 19 members of the bacterial community are shown