回归分析广义线性模型(Generalized Linear Model)glm
广义线性模型(Generalized Linear Model)是一般线性模型的推广,它使因变量的总体均值通过一个非线性连接函数而依赖于线性预测值,允许响应概率分布为指数分布族中的任何一员
- 二元分类响应变量的Logistic regression
- Poisson regression
- negative binomial regression
一个广义线性模型包含以下三个部分:
- ①随机成分。
- ②线性成分。
- ③连接函数g。
广义线性模型的参数估计一般不能用最小二乘估计(OLS Ordinary Least Square),常用加权最小二乘法或最大似然法(ML)估计,各回归系数β需用迭代方法求解。
glm(formula, family = gaussian, data, weights, subset, na.action, start = NULL, etastart, mustart, offset, control = list(…), model = TRUE, method = “glm.fit”, x = FALSE, y = TRUE, contrasts = NULL, …) 其中, formula为拟合公式,与函数lm()中的参数formula用法相同; family用于指定分布族,包括正态分布(gaussian)、二项分布(binomial)、泊松分布(poisson)和伪伽马分布(Gamma); 分布族还可以通过选项link来指定连接函数,默认值为family=gaussian (link=identity),二项分布默认值为family=binomial(link=logit); data指定数据集; offset指定线性函数的常数部分,通常反映已知信息; control用于对待估参数的范围进行设置。
已知count数服从泊松分布,相应的连接函数常用对数连接函数,模型可以写为
下面用R实现,首先建立数据集,分类变量直接输入定性的取值即可,glm()分析时会自动转换成矩阵X,注意参数family的写法。
R Markdown GLM 实现
library(MASS)
# install.packages("https://cran.r-project.org/package=HH")
# library(HH)
dat=data.frame(
cp_X=as.numeric(c(19.60204858,17.28012048,16.28012048,15.28012048)),
RA_Y=as.numeric(c(5.680165804,4.130875576,3.798621485,2.962170828))
)
#offset 已知?
dat.glm=glm(RA_Y~cp_X,data=dat,family=poisson(link=log))## Warning in dpois(y, mu, log = TRUE): non-integer x = 5.680166## Warning in dpois(y, mu, log = TRUE): non-integer x = 4.130876## Warning in dpois(y, mu, log = TRUE): non-integer x = 3.798621## Warning in dpois(y, mu, log = TRUE): non-integer x = 2.962171 summary(dat.glm) #glm的输出结果##
## Call:
## glm(formula = RA_Y ~ cp_X, family = poisson(link = log), data = dat)
##
## Deviance Residuals:
## 1 2 3 4
## -0.019680 -0.001019 0.108421 -0.090392
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.0089 2.5841 -0.390 0.696
## cp_X 0.1405 0.1471 0.955 0.339
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 0.914082 on 3 degrees of freedom
## Residual deviance: 0.020314 on 2 degrees of freedom
## AIC: Inf
##
## Number of Fisher Scoring iterations: 3#估计的回归系数都是非常显著的;Null deviance可以认为是模型的残差,它的值越小说明模型拟合效果越好;模型的AIC统计量为,它和deviance一起可以用来作为判断标准,选取合适的分布族和链接函数。
#下面通过作图来观察模型拟合的效果,首先提取模型的预测值,注意函数predict()提取的是线性部分的拟合值,在对数连接函数下,要得到Y的拟合值,应当再做一次指数变换。以实际观测值为横坐标,模型拟合值为纵坐标作图,散点越接近直线y=x,说明模型的拟合效果越好。
dat.pre=predict(dat.glm)
layout(1) #取消绘图区域分割
plot(dat$RA_Y,exp(dat.pre),xlab='观测值',ylab='拟合值',main="poisson 拟合效果",pch="*")+abline(0,1) #添加直线y=x,截距为0,斜率为1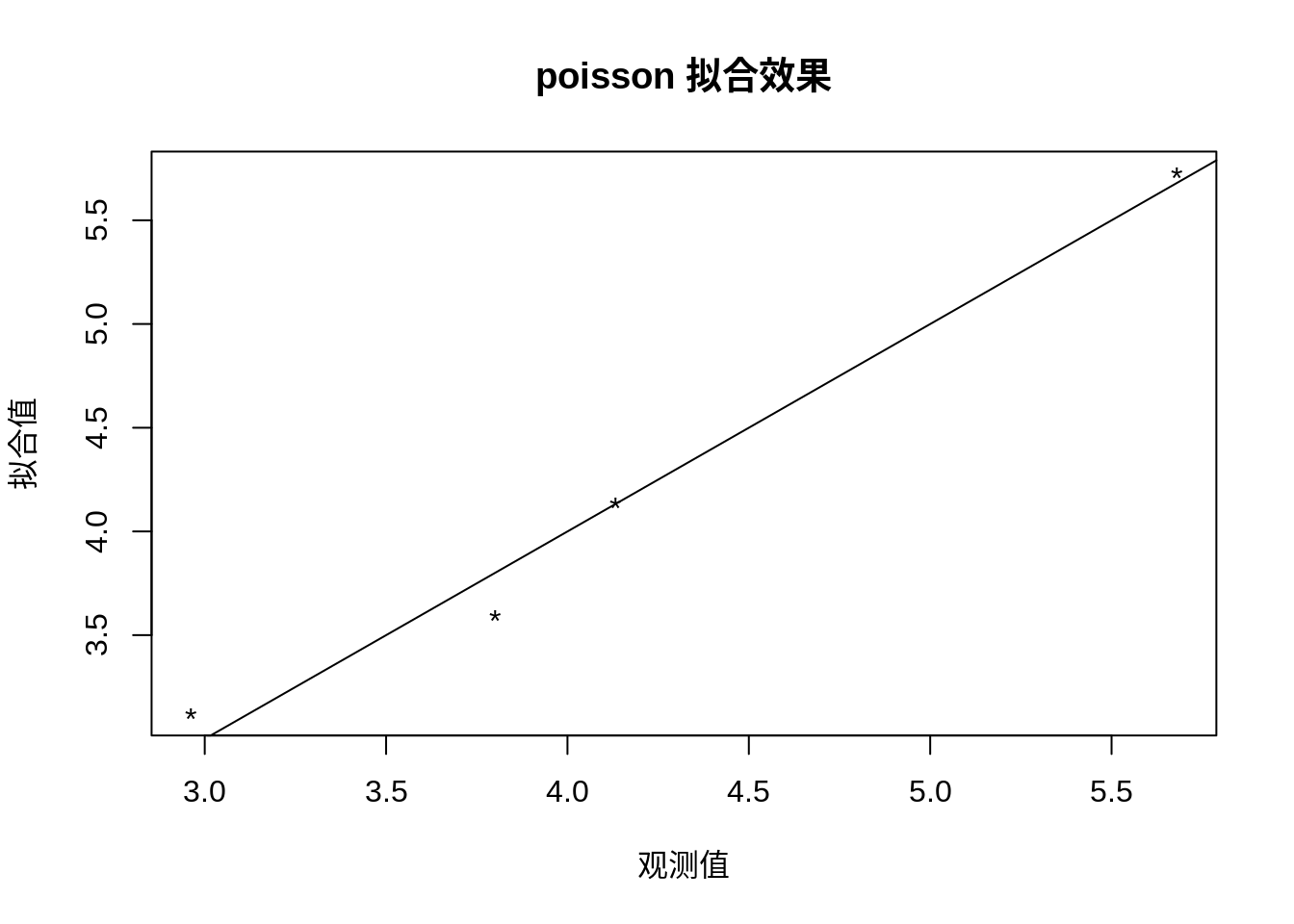
## integer(0)#若假设上例中的服从负二项分布,在R中应输入指令:
library(MASS)
attach(dat)
dat.glmnb <- glm.nb(RA_Y~log(cp_X),data=dat,link=log) #负二项回归## Warning in dpois(y, mu, log = TRUE): non-integer x = 5.680166## Warning in dpois(y, mu, log = TRUE): non-integer x = 4.130876## Warning in dpois(y, mu, log = TRUE): non-integer x = 3.798621## Warning in dpois(y, mu, log = TRUE): non-integer x = 2.962171## Warning in theta.ml(Y, mu, sum(w), w, limit = control$maxit, trace =
## control$trace > : iteration limit reached
## Warning in theta.ml(Y, mu, sum(w), w, limit = control$maxit, trace =
## control$trace > : iteration limit reached summary(dat.glmnb) #输出结果##
## Call:
## glm.nb(formula = RA_Y ~ log(cp_X), data = dat, link = log, init.theta = 14689888.7)
##
## Deviance Residuals:
## 1 2 3 4
## -0.01086 -0.02307 0.10087 -0.06892
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -5.615 7.401 -0.759 0.448
## log(cp_X) 2.472 2.589 0.955 0.340
##
## (Dispersion parameter for Negative Binomial(14689889) family taken to be 1)
##
## Null deviance: 0.914081 on 3 degrees of freedom
## Residual deviance: 0.015575 on 2 degrees of freedom
## AIC: 19.113
##
## Number of Fisher Scoring iterations: 1
##
##
## Theta: 14689889
## Std. Err.: 7710225144
## Warning while fitting theta: iteration limit reached
##
## 2 x log-likelihood: -13.113